
Duplicate detection/refactoring
To guarantee that models are built in compliance to quality criteria like modularity and maintenance as demanded by ISO/IEC 25000, model duplicates should be avoided by the developer. As the graphical editor of tools like MATLAB/Simulink ease the process of simply copying model parts and reusing it without documenting this reuse we implemented a duplicate detection method using the result of multiple duplicate detection approaches. These approaches are able to identify different kinds of duplicate grades:
- Grade 0: Exact model duplicate
- Grade 1: Duplicate only differs regarding layout and non-semantic attributes
- Grade 2: Duplicate also may differ regarding lieterals defined within a block
- Grade 3: Duplicate may also contain additional blocks or might miss some blocks contained in the duplicate base
We currently support three algorithms that cover all duplicate grades described above. We have implemented the ConQAT algorithm [1], the gapprox algorithm [2] and a duplicate detection approach based on layout informations.
The implemented algorithms have different results as they either compute duplicate pairs or duplicate groups containing one duplicate base and matching duplicate occurences. These results are merged into consolidated duplicate groups that contains each occuring duplicate only once. This eases the analysis of the result set.
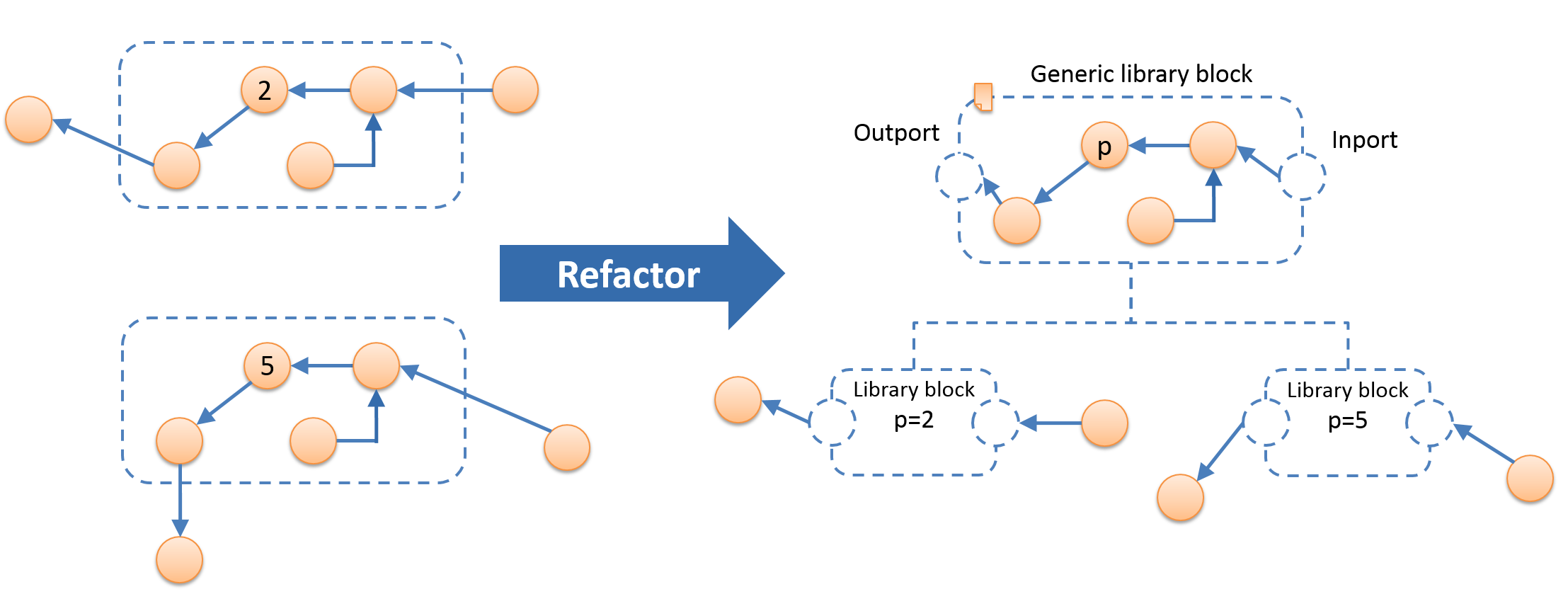
Detected duplicate groups can be refactored into a parametrizable library block as shown in the picture below. This is directly reflected within the analyzed MATLAB/Simulink models and is realized using the modification commands from the MATLAB/Simulink tooladapter. We published our findings at the MBEES2015 workshop [3].
[Bibtex]
@article{Deissenboeck2010,
author = {Deissenboeck, Florian and Hummel, Benjamin and Juergens, Elmar},
journal = {2010 ACM/IEEE 32nd International Conference on Software Engineering},
pages = {499--500},
title = {{Code clone detection in practice}},
volume = {2},
year = {2010}
}[Bibtex]
@inproceedings{Yan2002,
author = {Yan, Xifeng and Han, Jiawei},
title = {gSpan: Graph-Based Substructure Pattern Mining},
booktitle = {Proceedings of the 2002 IEEE International Conference on Data Mining},
series = {ICDM '02},
year = {2002},
isbn = {0-7695-1754-4},
pages = {721--},
url = {http://dl.acm.org/citation.cfm?id=844380.844811},
acmid = {844811},
publisher = {IEEE Computer Society},
address = {Washington, DC, USA},
}[Bibtex]
@inproceedings {Gerlitz2015,
author = { Gerlitz, Thomas and Schake, Stefan and Kowalweski, Stefan },
title = {{ Duplikatserkennung und Refactoring in Matlab/Simulink-Modellen [Duplicate Detection and Refactoring of Matlab/Simulink models]}},
booktitle = {{ 11. Dagstuhl-Workshop Modelbasierte Entwicklung eingebetteter Systeme (MBEES) }},
pages = { 17--27 },
year = { 2015 },
}